
Over the past few weeks we have discussed and seen how the modern dynamic web—and the digital humanities projects it hosts—comprise structured data (usually residing in a relational database) that is served to the browser based on a user request where it is rendered in HTML markup. This week we are exploring how these two elements (structured data and mark up) come together in a mainstay of DH methods: encoding texts using XML and the TEI.
XML (eXtensible Markup Language) is a sibling of HTML, but whereas the latter can include formatting instructions telling the browser how to display information, the former is merely descriptive. XML doesn’t do anything, it just describes the data in a regularized, structured way that allows for the easy storage and interchange of information between different applications. Making decisions about how to describe the contents of a text involves interpretive decisions that can pose challenges to humanities scholarship, which we’ll discuss more in the next class on the Text Encoding Initiative (TEI). For now, we’re going to explore the basics of XML and see how we can store, access, and manipulate data.
We went over the main parameters in class, but an excellent primer to XML in the context of DH has been put together by Frédéric Kaplan for his DH101 course and can be viewed in the slideshow below.
Introduction to XML from Frederic Kaplan
Text Analysis 101
Now that we know what XML markup looks like, we can turn to the broader and more fundamental question facing digital humanists: why should we mark up texts in the first place?
Computer-assisted text analysis is one of the oldest forms of digital humanities research, going back to the origins of “humanities computing” in the 1940s. Computers are well suited to data mining large bodies of texts, and with the rise of massive digitization projects like Google Books, many research questions can be answered using plain “full text” versions of documents. The Google Ngram viewer is probably the best known of these tools, allowing simple comparisons of the frequencies of words across Google’s enormous corpus of digitized texts. Someone interested in Prohibition for instance might compare the frequency of “alcohol” and “prohibition” in the American English corpus to see how the two terms were used during the period of its enforcement.
More sophisticated text analysis tools also exist that let you perform some pretty impressive data mining analytics on plain texts. Voyant Tools is one of the most well known and useful tools out there, that will permit some pretty impressive analysis and visualization on plain texts, but also allows you to upload XML and TEI files that permit fine tuning of your data. For how-to information, check out their extensive documentation page.
Exercise (Plain Text Analysis)
Let’s take a look at what these text analysis tools can do with a classic example text: Shakespeare’s Romeo and Juliet.
- Go to Voyant Tools, click the Open folder icon and choose Shakespeare’s Play’s (Moby) to load the open-access plain-text versions of all the Bard’s plays.
- Explore the interface, read the summary statistics and hover your mouse over various words to see what pops up
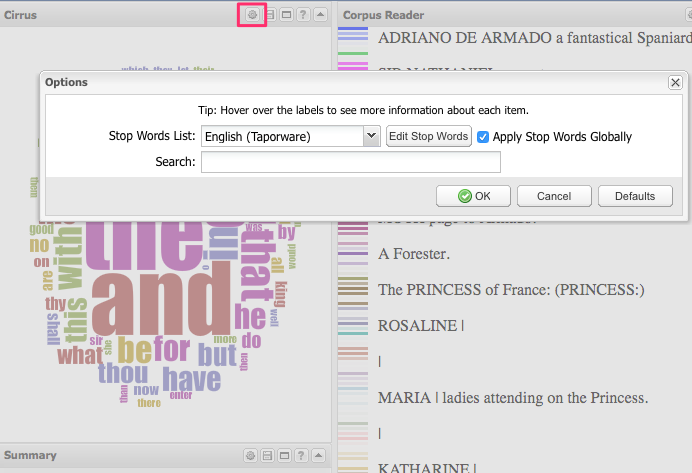
- What do you notice about the Cirrus tag cloud?
- To make it more useful, add a stop word list, “a set of words that should be excluded from the results of a tool”
- Click the gear icon to launch the options menu
- Choose the English list, which contains all the common short words, prepositions and articles in modern English. Since this is Shakespeare you’ll still be left with a lot of thees, thous, and thys, and if you wanted you could go back into the options, click “Edit Stop Words” and manually add more words to the list.
- Click on any word to launch more tools and investigate what they tell you and continue to explore the possibilities that Voyant offers.
- Open the Documents window at the bottom, and click on Romeo and Juliet to load just that play’s statistics
- Investigate the Word Trends, and Keywords in Context tools to analyze some key thematic words in the play, like “love” and “death”
- There are a number of other analysis and visualization tools that Voyant offers, which can be accessed via a direct URL in the address bar.
- See docs.voyant-tools.org/tools/ for a complete list
DISCUSSION:
- What kinds of questions can you answer with this sort of data?
- Are there research topics that would not benefit from the approach?
Text analysis and data mining tools can get a lot of statistics out of the full texts, but what if we are interested in more fine grained questions? What if we want to know, for instance, how the words Shakespeare used in dialogues differed from soliloquies? Or what if we were working with a manuscript edition that was composed by several different hands and we wanted to compare them? For these kinds of questions, we need to go beyond full text. We need to encode our texts with meaningful tags. Enter XML and TEI.
For humanities projects, the de facto standard markup language is that specified by the Text Encoding Initiative. They have spent years working out a flexible yet consistent system of tags with the aim of standardizing the markup of literary, artistic and historical documents to ensure interoperability between different projects, while at the same time allowing scholars the discretion to customize a tag set matching the needs of their specific project. This flexibility can make it a daunting realm to enter for newbies, and we will not be going very far down this path.
The best gentle introduction to getting a TEI project up and running can be found at TEI By Example. For our purposes, let’s see how a properly marked up version of Romeo and Juliet differs from the plain text version and what that means for our scholarly pursuits.
Exercise (Encoded Text Analysis)
The Folger Shakespeare Libary’s Digital Texts is a major text encoding initiative that provides high quality digital editions of all the plays online for free. These are not only available online through a browser, but the Folger has also made their source code available for download.
- First, look at the online edition of Romeo and Juliet in formatted HTML.
- This provides a much nicer reading experience than a plain text version, mimicking the print edition, but adds search and navigation
- Explore these features and think about what this presentation offers compared to a traditional print version
- This provides a much nicer reading experience than a plain text version, mimicking the print edition, but adds search and navigation
- To see how they made this happen, download the XML source code and open it in the finder.
- Using your new knowledge of XML, XSLT, and CSS open the files in a text editor and try to make sense of them.
- For the XML file, you’ll see that this is much more complex than the RSS feed we looked at before.
- What elements have they tagged? How fine-grained did they get? Why?
- You may find their Tag Guide documentation helpful to understand what each element represents
- Using the guide, try to locate a speech by Romeo and another by Juliet.
As you might imagine, this kind of granularity of markup opens the door to much more sophisticated queries and analyses. Let’s say, for instance, that we wanted to compare the text of Romeo’s speeches with those of Juliet as part of a larger project exploring gender roles on the Elizabethan stage. The detailed TEI encoding of the Folger edition should let us do this pretty easily. Unfortunately the user interfaces for analysis of TEI documents have not been developed as much as the content model itself, and most serious analytical projects rely on statistical software packages used in scientific and social science research, like the open-source R. We’re not going to go that route for this class.
Voyant Tools will allow us to select certain elements of the marked up code, but only if we understand the XML document’s structure and know how to navigate it with XPATH (part of XSL and used in conjunction with XSLT). So let’s see how that works on our Romeo and Juliet example.

To do so, we’re actually going to use a slightly simpler XML markup version of Romeo and Juliet, so that it’s easier to see what’s going on.
- Go back to Voyant Tools and paste the URL below into the Add Texts box
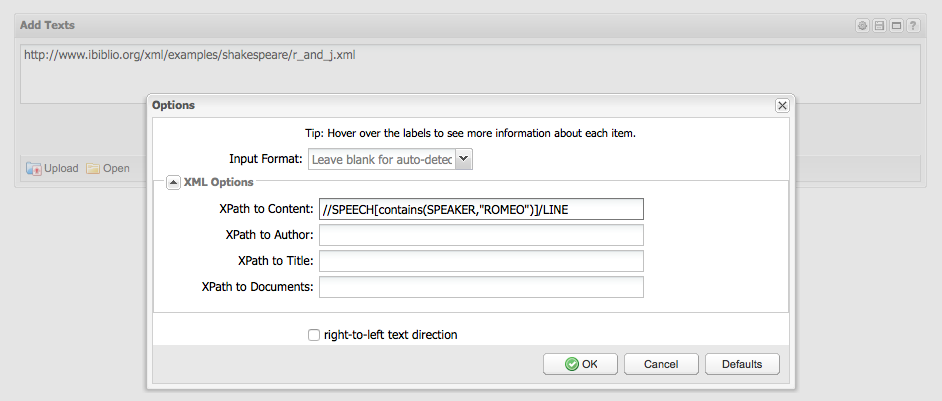
- Before you click Reveal, open the Options dialog in the top right corner
http://www.ibiblio.org/xml/examples/shakespeare/r_and_j.xml

- Under “XPath to Content“, type (or copy/paste) the following expression
//SPEECH[contains(SPEAKER,"ROMEO")]/LINE
- Let’s also give this document the Title of ROMEO
- Under “XPath to Title“, try to alter the expression above to select the SPEAKER values within Romeo’s speeches, instead of the LINE values
- Finally, click on OK, and then Reveal
- Apply your stop words and explore how this differs from the full text version of the play we examined earlier
I’m sure you can see the powerful possibilities afforded by using the encoded tags to quickly select certain portions of the text. When you do this type of analysis on an entire corpus, you can generate lots of data to compare with relative ease. So let’s compare Romeo’s text to Juliet’s
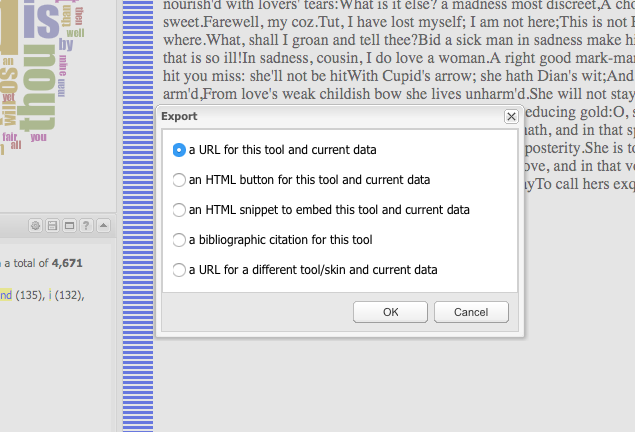
- To preserve Romeo’s text analysis, we can get a static URL to this instance of Voyant.
Now you can go back to the home screen and repeat the process above, making changes to the Path expressions in order to get all of Juliet’s lines and title the new document JULIET.
- Apply your stop words again
- Now you can use all of the analytical tools to compare the two lover’s words!
Now that we’ve seen an example of a large TEI project and gotten a glimpse of the analytical power detailed markup affords, let’s think through the interpretive implications of deciding on a tag set for a project.
The content model for any given document is decided on by the interpreter, so your first task is to figure out what questions you think the document will be used to answer. As you might imagine, this up front work will shape the final outcome and must be considered (and carefully documented!) when starting a new project.
Exercise (TEI)
- Search the Carleton digital collection for a postcard from before 1916
- Try to find one that has images of both the front and back, and that includes a hand-written message in addition to the printed image.
- Have a look at the TEI Lite tag set and try to come up with some meaningful tags to mark up both the front and back in one encoded transcription.
- This tutorial on encoding primary sources at TEI by Example will be helpful as you try to figure out what tags to apply for figures, multiple “hands” as authors, etc.
- Consult your neighbors and then compare with another group.
- How did you do? Would your individual mark up efforts combine to form a usable corpus, or would you need to do some adjusting?
Resources
- Voyant lists many more examples of how people use the tools in their Examples Gallery.
- The main TEI site has links to a ton of documentation on the Initiative, including many how-tos.
- The TEI at Oxford teaching pages also contain a lot of slides and exercises from previous workshops, in many of which you can see witness prominent TEI members Lou Bernard and Sebastian Rahtz wrestling with the challenges of maintaining the TEI’s dual goals of flexibility and interoperability.
- Some notable TEI projects include:
- The Mark Twin Project: http://www.marktwainproject.org/
- The Newton Project: http://www.newtonproject.sussex.ac.uk/prism.php?id=1
- Documenting the American South: http://docsouth.unc.edu
- World of Dante: Worldofdante.org
Resources
XML DOM and JavaScript
w3schools is always a good place to start for the by-the-book definition of a language or standard with some good interactive examples, and their XML DOM tutorial is no exception.
SimpleXML in PHP 5
If your project allows server-side scripting it is MUCH easier to use PHP to parse XML than JavaScript. The w3schools introduction to simpleXML in PHP 5 is solid, but TeamTreehouse.com has a more readable and accessible real-world example of how to parse XML with php’s simpleXML functions.
XSLT
XSLT (eXtensible Stylesheet Language Transformations) is to XML what CSS is to HTML, but it’s also a lot more. More like a programming language within markup tags than a regular markup language, it’s a strange but powerful hybrid that will let you do the same things as the languages above: transform XML data into other XML documents or HTML. Learn the basics at w3schools’ XSLT tutorial. If you’d like a more in depth explanation of how XML and XSLT work together check out this tutorial xmlmaster.org, which is geared at the retail/business world but contains basic information relevant for DH applications.
Final Assignment 1 (Project Pitch)
Form a group of 2-3 and chose or invent a project. Collectively write a blog post on the course blog, stating the following:
- Members of the group
- The definition of the project topic and objectives for what you plan to produce
- The proposed methodology:
- What data do you hope to use and how do you hope to find it?
- What tools and techniques will you use to gather sources and store your data?
- What analyses or transformations will you conduct on those data?
- How will you present the results and integrate the digital assets you create as an interactive final product?
- The proposed timeline of deliverables
- And finally, a link to one or more DH projects that you think might make a good model for what you plan to do.
Create a unique tag for your group to tag all your posts going forward.
On your own blogs, write a brief message outlining your personal interests in the projects and what you hope it will achieve, and link to it from the group’s post

{kind=link}
{kind=link}
{kind=link}
{kind=link}