
Big Data generally refers to extremely large datasets that require demanding computational analysis to reveal patterns and trends, such as the map below generated from the data in millions of Twitter posts. We are producing reams of this data in the 21st century, but how do we analyze it from a humanities perspective? How do we perform these sorts of analyses if we are interested in periods before regular digital record keeping?

Enter digitization and citizen science initiatives. One of the major trends in Digital Humanities work is the digitization of old records or print books that are then made searchable and available online for analysis. Google Books is the most well-known project of this type, and we also read Tim Hitchcock’s article about his pioneering historical projects in this arena, e.g. the Old Bailey Onlineand London Lives. These projects took years to build and required the dedicated paid labor of a team of scholars and professionals. But there’s another model out there that relies on the unpaid labor of thousands of non-expert volunteers who collectively are able to do this work faster and more accurately than our current computers: crowdsourcing.
Zooniverse is a crowdsourcing initiative that bills itself as “the world’s largest and most popular platform for people-powered research.” This platform takes advantage of the fact that people can distinguish detailed differences between images that regularly trip up computers, and empowers non-experts to contribute to serious research by reducing complex problems to relatively straightforward decisions:
- is this galaxy a spiral or an ellipse?
- is this a lion or a zebra?
- is this the Greek letter tau or epsilon?
One recent project from the University of Minnesota, Measuring the Anzacs, seeks to study demographic and health trends in the early 20th century by transcribing 4.5 million pages worth of service records from the Australian and New Zealand Army Corps during WWI. This data would take countless years to process with a small team of researchers, but they hope to speed up this process tremendously by taking advantage of the fact that there are lots of people who have access to a computer, speak English and can read handwriting.
Tim Hitchcock ended his piece with a conundrum:
How to turn big data in to good history? How do we preserve the democratic and accessible character of the web, while using the tools of a technocratic science model in which popular engagement is generally an afterthought rather than the point.
The Zooniverse model has taken a major step towards resolving this tension and turning formerly restricted research practices into consciously public digital humanities work.
In Class
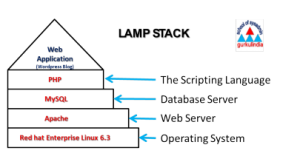
For today, we are interested primarily in exploring how relational databases work in a typical DH project, which often shares a lot of similarities with how web applications work in general. So we are going to stick with what we already know and get to know databases by exploring the backend of a WordPress site.
If you were going to do this the old fashioned way, you would need some space on a server running the LAMP stack (Linux, Apache, MySQL, and PHP) to install and run a fully customizable WordPress site, but we are going to using our cPanel in Reclaim Hosting which takes care of all the system administration work for us.

Most web applications and DH projects consist of two main components: files and a database. The main WordPress files you’ll interact with are the PHP files in the theme layer, which change the look and feel of your site, and the plugins in the plugins directory, which add functionality. Check out the Resources section below for more on how to customize these.
The database can be accessed via phpMyAdmin, a super helpful tool that lets you interrogate and take actions on the database without having to type SQL commands directly into a shell prompt.
- Explore your WordPress db, consulting the diagram at right,
- See if you can figure out how the data and metadata of a typical post, page and comment are broken up and stored in the db.
- Add a new plugin and a new theme to your site.
- Did either change the database? Which one? Why?
Continue to explore the guts of WordPress and ask yourself: how are the data are structured, stored, and ultimately rendered in the browser? Do you understand all the component parts?
Assignment
The assignment for this week is twofold:
First, make sure you have registered your domain and installed WordPress, and then spend some time setting up your personal website on your newly installed server. These are the most basic steps you should take to get your site looking like personalized rather than a generic WordPress blog.
- Create an “About” page (not Post) to let the world know who you are
- Write a brief bio paragraph about your background, what you are studying, your goals, etc. and post it to the site. See mine at meDHieval.com for an example.
- Get an API key for the Akismet plugin and activate it to block comment spam.
- You can follow these instructions from Brian Croxall and the good folks at Emory
- Choose a new theme to install and activate it
- Add the Simple Custom CSS plugin and use your DevTools skills to change at least one element of your site’s design via CSS code
- If you need help with installing plugins, or want to install more, follow Emory’s instructions
Secondly, continue exploring the server environment on your own, and try to see if you can understand how the different pieces fit together within the LAMP stack itself and within the MySQL relational databases.
Continue
- Continue to explore the WordPress backend and think about what this structure allows.
- Try to reproduce and populate some of the database that Stephen Ramsay describes in this article on your local host by either executing the SQL statements or using the phpMyAdmin graphical user interface that comes on your host.
- Finally, write a blog post that discusses the benefits and drawbacks of flat data structures like spreadsheets vs. relational databases.
- What are the pros and cons of each?
- What issues with data collection and metadata must be considered and solved before you get too far?
