You can find the visualizations and analysis at http://dh.library.yale.edu/projects/vogue/.
The project consists of multiple processes and presentations conducted on 6 terabytes of sources. This project is unique in the array of diverse processes and presentations. The large amount of assets and the flexibility of the data lead the path to many unique specific types of analysis. Projects range from word based analysis to color pattern recognition to even circulation and advertising reports.
The diverse processes and presentations are all possible because of the one of a kind dataset. The Robots Reading Vogue project pulls from ProQuest’s The Vogue Archive (http://www.proquest.com/products-services/vogue_archive.html). The Vogue Archive consists of 6 terabytes of Vogue magazines dating back to 1892 and updated each month with the new release. This is a unprecedented representation and glimpse into the world of fashion, pop culture, gender, and advertisements tracked throughout the years.
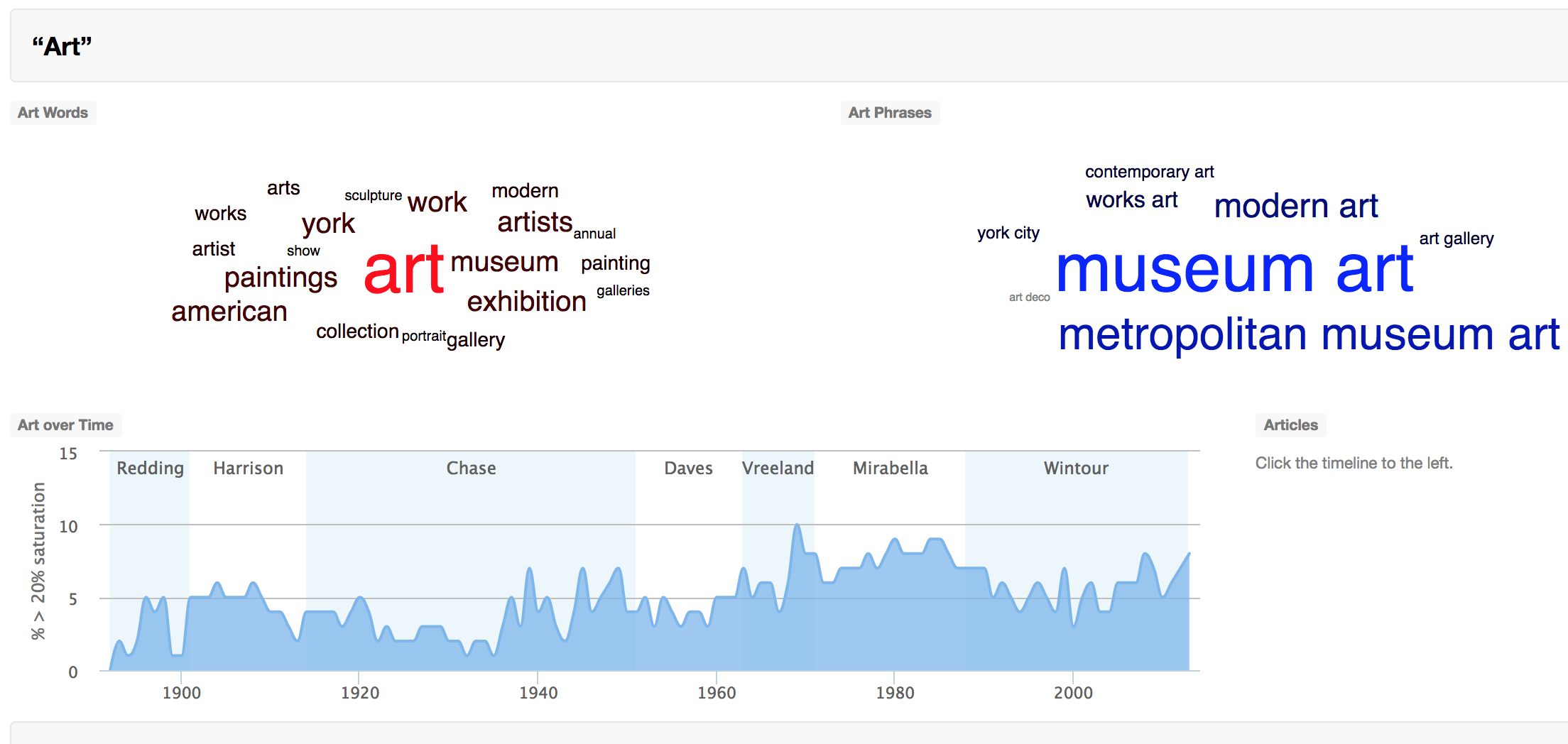
If I were to focus in on Topic Modeling, a specific presentation I can break down the black box surrounding it’s implementation. The Topic Modeling project processed through all the assets and found the twenty most common themes (I.E. art, travel, food, politics, culture, and many others). Then using clustering created word cloud visualizations with words and phrases associated to the themes. Then, it graphed the popularity of the themes overtime in relation to other issues over the years. The x axis contained the year and the current creative director, while the y axis displayed the saturation percentage.
How did they determine the most common themes? Was it run through a database or did they decide before doing any other projects?