The Georgetown Slavery Archive is a project created by the Archives Subgroup of the Georgetown University Working Group on Slavery, Memory, and Reconciliation. This digital archive preserves and aggregates documents concerning the Maryland Jesuits, Georgetown University, and Slavery. The project also reaches out to descendants of slaves owned by Maryland Province Jesuits to collect, preserve, and tell the stories and histories of those families. To explain how the site is constructed, I’ll be breaking it down using Miriam Posner’s method, as detailed in this video on her blog.
Sources:
The documents in the archive were sourced from the Maryland Province Archives of the Society of Jesus, the Booth Family Center for Special Collections, and the Georgetown University Library. Also included are the stories and personal histories of the discovered descendants of slaves owned by Maryland Province Jesuits.
Process:
In order to create the digital archive, all of the documents had to be scanned and digitized, transcribed, geotagged, and broken down into groups that would later become the site’s five collections. The stories of the descendants underwent similar processes. Each item in the archive is tagged by Title, Subject, Description, Creator, Source, Publisher, Date, Contributor, Rights, Format, Language, Type, Identifier, and Collection. Additionally the archive provides Metadata for each item as well as the original format of the document.
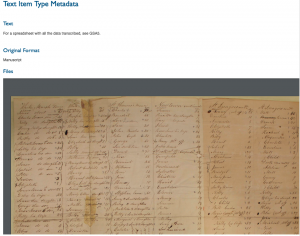
Presentation:
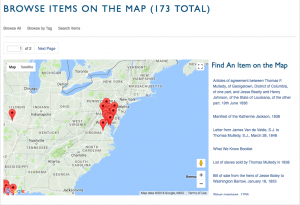
The data in the archives are organized and presented in a variety of ways. A selection of documents from the Georgetown Slavery Archive are presented in a Gallery, where the users can browse by selecting a thumbnail or the name of the scanned document . The Archive’s Inventory can be changed to be presented in chronological order, and contains a complete inventory of materials on the site. These materials have an identifier tag and short description on the inventory page, while the identifier links to the document and its complete informational breakdown as mentioned in the Process section of this post. The archive can also be searched by five thematically broad Collections: Descendants’ Stories, The Maryland Province Slaves in Louisiana and Their Descendants, Slavery at Georgetown University, Slavery in the Maryland Province, and Sale of Maryland Jesuit slaves to Louisiana in 1838. The main visual component to the archive is a Map of the locations that uses Google Maps. The site itself was created and runs on Omeka, a project that “provides open-source web publishing platforms for sharing digital collections and creating media-rich online exhibits.”
Thanks for reading! I hope you learned more about this project and it’s organization.
I really like the website organization! It is easy to understand. The project itself is also interesting and helpful in cataloging information about slavery digitally. Especially, the further reading section would be beneficial for readers who are interested in knowing more about the topic through outside sources.
Your information was more organized than mine. How long did it take to find the information?