Big Data generally refers to extremely large datasets that require demanding computational analysis to reveal patterns and trends, such as the map below generated from the data in millions of Twitter posts. We are producing reams of this data in the 21st century, but how do we analyze it from a humanities perspective? How do we perform these sorts of analyses if we are interested in periods before regular digital record keeping?

Enter digitization and citizen science initiatives. One of the major trends in Digital Humanities work is the digitization of old records or print books that are then made searchable and available online for analysis. Google Books is the most well-known project of this type, and we also read Tim Hitchcock’s article about his pioneering historical projects in this arena, e.g. the Old Bailey Onlineand London Lives. These projects took years to build and required the dedicated paid labor of a team of scholars and professionals. But there’s another model out there that relies on the unpaid labor of thousands of non-expert volunteers who collectively are able to do this work faster and more accurately than our current computers: crowdsourcing.
Zooniverse is a crowdsourcing initiative that bills itself as “the world’s largest and most popular platform for people-powered research.” This platform takes advantage of the fact that people can distinguish detailed differences between images that regularly trip up computers, and empowers non-experts to contribute to serious research by reducing complex problems to relatively straightforward decisions:
- is this galaxy a spiral or an ellipse?
- is this a lion or a zebra?
- is this the Greek letter tau or epsilon?
One recent project from the University of Minnesota, Measuring the Anzacs, seeks to study demographic and health trends in the early 20th century by transcribing 4.5 million pages worth of service records from the Australian and New Zealand Army Corps during WWI. This data would take countless years to process with a small team of researchers, but they hope to speed up this process tremendously by taking advantage of the fact that there are lots of people who have access to a computer, speak English and can read handwriting.
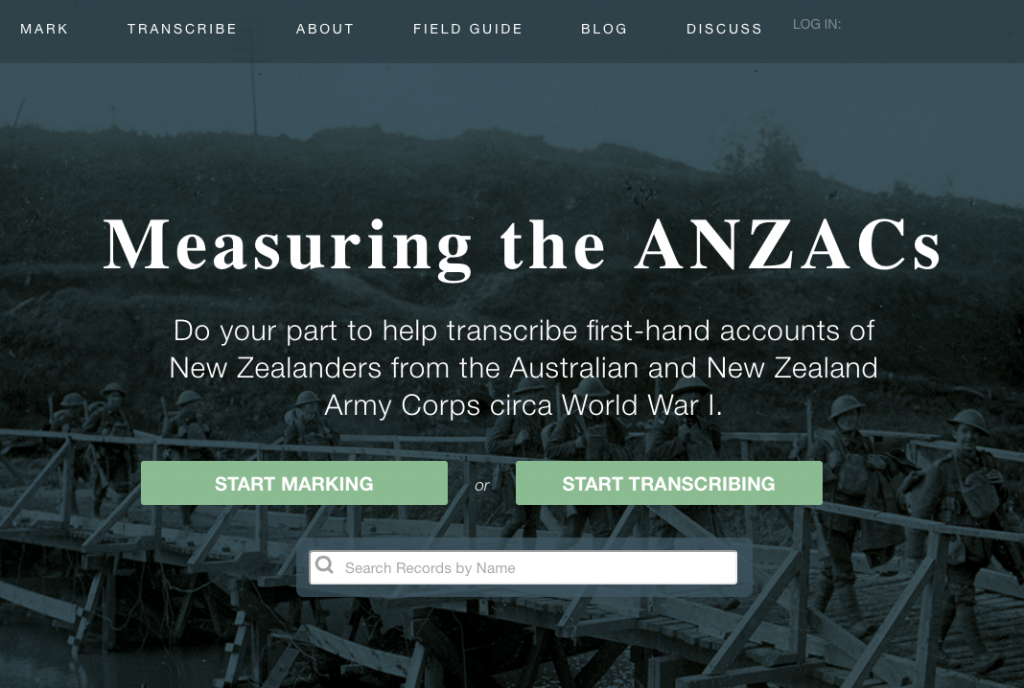
Tim Hitchcock ended his piece with a conundrum:
How to turn big data in to good history? How do we preserve the democratic and accessible character of the web, while using the tools of a technocratic science model in which popular engagement is generally an afterthought rather than the point.
The Zooniverse model has taken a major step towards resolving this tension and turning formerly restricted research practices into consciously public digital humanities work.
In Class: Crowdsourcing
Try your hand at contributing to a crowdsourcing project!
Explore the Zooniverse projects page and filter for an Arts or Humanities discipline that interests you.
Choose a project, follow it’s instructions, and contribute some labor to its data collection.
When you’re done, post a brief comment below giving some feedback on the process by answering one of the following questions.
- Were the instructions easy to follow?
- If transcription based, was the text easy to transcribe?
- If not, what work did you do?
- Did you feel like you were making a real contribution to the project?
- What did you get out of the project, from a humanities perspective?
- Are there ethical issues with relying on unpaid labor in this way?
The Database Back End
In our continuing quest to explore what goes on “under the hood” of digital humanities projects, this week we are moving from the front-end client-side user experience to the database “back end” on the server side, where all the data storage and information retrieval magic happens. In order to perform analysis, or present the results of our research to the public on the web, we first need to collect, categorize and store our data in a way that will give us the best combination of structure and flexibility.
You can use a simple flat spreadsheet to store enough data to power some pretty impressive applications using JavaScript alone, like using the Google Maps API or the beautiful TimelineJS framework.
In the past, students in this class used the TimelineJS framework to make Timeline of Carleton History, and the backend was nothing more than a simple Google Sheet.
This works great for the timeline, but what if we wanted to do different things with the same data? What if we wanted to reorder our data by something other than chronology, or extract all the people or buildings, or add spatial locations? And what if we wanted to model the relationships between those elements? Our spreadsheet is just not flexible enough for this. In order to store complex data sets, we need a more sophisticated way to store it; enter the relational database.
There is a vast amount of literature out there on database design theory and practice, but the articles we read for this week provide a good starting point into the general characteristics of relational databases, and the raging debates over how to move beyond them in the brave new world of ‘big data‘ in humanities research.
The key takeaway from these debates is that “data” are not value free and neutral pieces of information. Any time we break information down and classify it into categories, we are imposing our human world view and experiences on the information, whether consciously or not. This is unavoidable, but the best way to deal with it honestly is to acknowledge our biases, document our decisions and explain our thinking at each step of the process. The resulting metadata (data about the data) are critical for successful scholarly projects, and we will discuss their importance throughout the course.
For today though, we are interested primarily in exploring how relational databases work in a typical DH project, which often shares a lot of similarities with how web applications work in general.
SIDE NOTE: In the past few years, there has been an increasing call to move away from CMSes and database-driven sites and back towards static websites. This is not pining for the bad old days, but instead relying on the increasing number of static site generators like Jekyll that let you build the site locally on your machine and push static HTML to a host rather than reacting to user requests and populating HTML with content as in most database-backed web sites. While there are many benefits to this approach, especially for fairly simple sites like blogs and those without much user interaction, there are some drawbacks to static site generators for DH projects, knowing how databases interact with client side systems is still a valuable skill, which we will be focusing on in this course.
In Class: Setting up Your Own Server
For today, we are interested primarily in exploring how relational databases work in a typical DH project, which often shares a lot of similarities with how web applications work in general. So we are going to stick with what we already know and get to know databases by exploring the backend of a WordPress site.
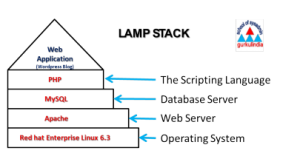
If you were going to do this the old fashioned way, you would need some space on a server running the LAMP stack (Linux, Apache, MySQL, and PHP) to install and run a fully customizable WordPress site, but we are going to using our cPanel in Reclaim Hosting which takes care of all the system administration work for us.
Follow these instructions to register a domain and install your own WordPress site.
Most web applications and DH projects consist of two main components: files and a database. The main WordPress files you’ll interact with are the PHP files in the theme layer, which change the look and feel of your site, and the plugins in the plugins directory, which add functionality. Check out the Resources section below for more on how to customize these.
The database can be accessed via phpMyAdmin, a super helpful tool that lets you interrogate and take actions on the database without having to type SQL commands directly into a shell prompt.
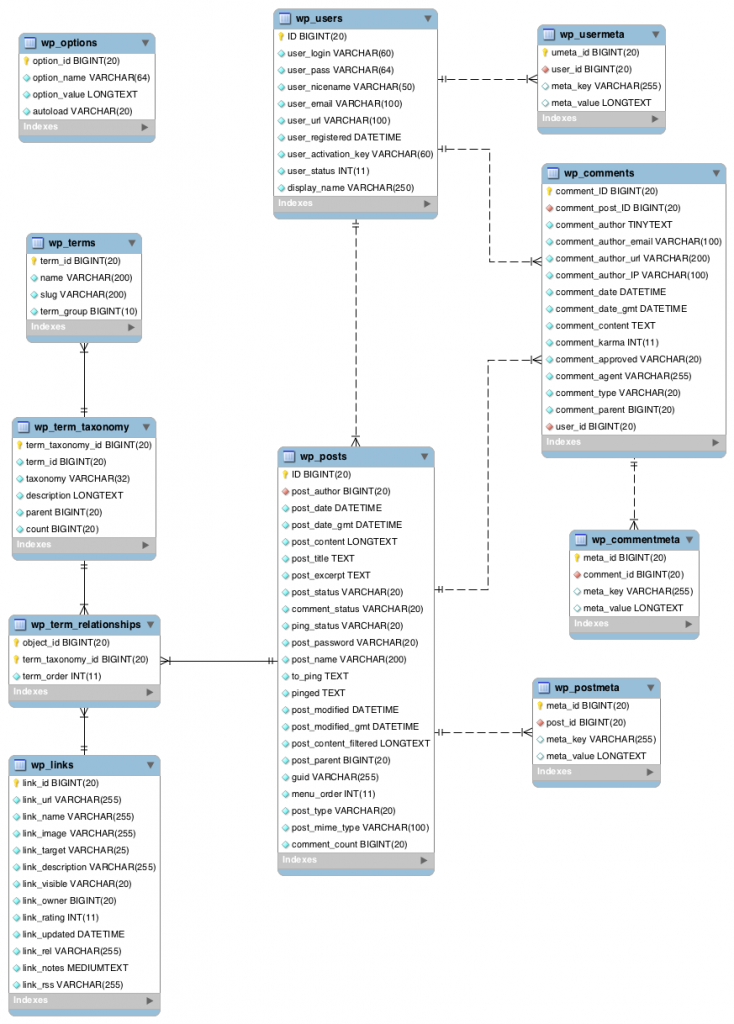
- Explore your WordPress db, consulting the diagram at right,
- See if you can figure out how the data and metadata of a typical post, page and comment are broken up and stored in the db.
- Add a new plugin and a new theme to your site.
- Did either change the database?
- Which one?
- Why?
Continue to explore the guts of WordPress and ask yourself: how are the data are structured, stored, and ultimately rendered in the browser? Do you understand all the component parts?
Assignment
The assignment for this week is to get to know your new hosting environment by setting up your own WordPress site with full administrator controls:
First, make sure you have registered your domain and installed WordPress, and then spend some time setting up your personal website on your newly installed server. These are the most basic steps you should take to get your site looking like personalized rather than a generic WordPress blog.
- Create an “About” page (not Post) to let the world know who you are
- Write a brief bio paragraph about your background, what you are studying, your goals, etc. and post it to the site. See mine at meDHieval.com for an example.
- Protect your site from comment spam, by activitating the Akismet plugin.
- You can follow these instructions
- Choose a new theme to install and activate it
- Add the Simple Custom CSS plugin and use your DevTools skills to change at least one element of your site’s design via CSS code
- If you need help with installing plugins, or want to install more, follow the helpful guide at UMW’s Domain of One’s Own help site
Finally, write a short blog post introducing your new site discussing your experience setting up your own WordPress install.
- What might you do with this platform?
- What benefits or drawbacks come with “rolling your own” website instead of signing up for a hosted service or using a social media platform?
30 replies on “Big Data and Data Storage”
I chose the SCOTUS notes project, and although the instructions were quite easy to follow, I struggled to read and transcribe the writing of the Supreme Court justices. I can’t say that I felt like I made a major contribution as I imagine that there’s a large pool of notes that need transcribing.
To be honest, working on documents from the 1980s is significantly nicer than most of the documents I’m used to. I worked on the Castaway research vessel sheets and the numbers there are much more legible and nicely organized than the trial records from the Irish rising of 1641 for example.
It’s very easy. I’d heard of stuff like this before and it’s really cool. I looked for “clumps” in pictures of galaxies from Hubble’s Galaxy Zoo project.
Honestly I think I screwed it up a little. I clicked the wrong thing a couple times and couldn’t go back. Luckily these pictures get reviewed by multiple people.I hope I made a contribution to the project but I don’t really feel like I did. I don’t think I really got anything out of the project from a humanities perspective. I just don’t really think I did.
I don’t think there are any ethical issues here. It’s practically a game. Add a pop up that tells you how great you’re doing to give that jolt of dopamine and it would easily appeal to lots of people as a game.
Here’s the thing: Given how easy it was for me to mess up on a project that wasn’t even writing, just clicking, it would be easy as hell for someone to troll this kind of work. I think the only thing stopping them is lack of knowledge about the site.
Was the transcription easy to read?
I transcribed information from records of Australian criminals of the early 20th century. Their records were mostly legible, but I can see how reading the records could be very difficult. The illegibility of the criminals’ writing could harm the data, but Zooniverse prevents this as much as possible by taking the most popular answers from the community.
After attempting to spot the rare Otago skink, one of New Zealand’s critically endangered animals, I am sad to announce that I could not observe any Skinks. I found this task to be rather difficult, as if I was not making any real contribution to the project itself. While I am not sure what humanities subject this contributes to, I am sure the observation and subsequent preservation of Skinks is of the utmost priority.
Instructions were clear and easy to follow. The transcription based projects were hard. Those texts were really hard to transcribe. I not quite get the rewarding feedback of making a real contribution to the project. But humanities scholars need to transcribe these raw materials into digital database. It made me bored to do projects in this way without paying.
This is a really really cool exercise. I did not know consider the fact that people could rely on the internet to transcribe prison records from the early 1900s onto the internet. It’s great. Also, especially with the transcribing prison record project, they’re taking consensus from general public to avoid a couple bad readers from entering inaccurate data.
I’m interested to learn more about the quality of data gathered through crowd sourcing projects. I think that would give me a better idea of how much I was helping these projects
I contributed to the Floating Forests project identifying patches of kelp. What I had to do was highlight with a pen tool where the patches of kelp were on the map. It felt like something that would be useful and extremely tedious for someone with experience to be doing but I question how accurate their data is. I don’t think there are ethical questions since it is volunteer based, but one solution could be to give small amounts of compensation, I know Amazon does something similar with paying people a very small compensation for completing surveys. This could also reduce some of the bad data if you are forced to sign in and your submissions can be tracked.
The instructions were relatively simple to follow, as the the tutorial for each project was pretty descriptive. In the examples I encountered, most of the text was easy to transcribe plus legible. For some of the more difficult transcriptions like deciphering habitat location, I did feel like I was making some contribution to the work, as a computer might have had some trouble. It is truly amazing how data analyzation of fields in the humanities can be easily benefitted by technological processes online. All around, it was fun all around and voluntary, so I don’t find it necessarily unethical.
I worked on transcribing Australian convict records. Personally, I found the handwriting easily understandable, but I’ve also transcribed documents before. Overall, the instructions were easy to understand it was simple to understand what they were asking for and clear how I was to respond. I didn’t particularly think that I was doing meaningful work, but I understand that my responses added to others becomes significant.
It was very difficult to read judges notes from court cases. Maybe context would’ve helped decipher some things, but generally it would not pass an elementary school handwriting test. The idea of crowd-sourced research is really cool to me, though! I wonder what kind of people like to spend their time doing these.
I worked on the Anti-Slavery Manuscript project. Deciphering the text was difficult, especially when it was a name because there was uncertainty as to whether I was misreading the text or it was simply a different spelling of a name. I think that the way the project has of having multiple readers check each document is a good way to mitigate human error, though I’m curious to see what standards they used to declare a certain section ‘done,’ or no more feedback needed. Was this checked by a person or was a certain amount of data taken it and then it was decided that was enough?
My project, “Worlds of Wonder” involved identifying or not an image on the pages of a scanned book. When spotting a figure, assign it tags. It was fairly easy and the tutorial was surprisingly quick. The quickness of the process was engaging and motivating to keep me answering the questions. This could, however, pose a problem to the accurateness of the answers seeing that one might just breeze through the responses without giving them much thought.
For me transcribing criminal records was a little hard because I couldn’t understand the writing. However, I was reassured by the fact that they made it very clear that I wasn’t the only one transcribing the document and that the final result would be a consensus of various entries.
The project I worked on has high-quality instructions; however, these instructions can be boring to read so as a result I personally would not volunteer for these projects.
I followed the “Criminal Characters” project which had me transcribe Australian prison records. The project offered two options – one only had me transcribe part of a record and the other had me transcribe the whole thing. The instructions were easy to follow, and it was nice that they offered a shorter option, especially for an activity like this where we only have so much time. That being said, it was a little difficult to read the handwriting in the records, but the project explained in multiple ways that it was okay if you typed an unsure answer as other people are there to double check it.
Were the instructions easy to follow?
The instructions were definitely easy to follow, if somewhat difficult to actually visualize on the project itself. The organizers of each project clearly try to make the set-up user friendly, so that it is at least clear what you are supposed to do and how to do it. The issues stemmed more from handwriting issues rather than a lack of clarity on my job.
If transcription based, was the text easy to transcribe?
No! I would assume that computers are not reliable for the task of OCR and transcription, seeing as some of the words are nearly impossible to discern or understand just by sight alone.
To specify, I worked on the “Measuring the AZTACS” project
I did the Asteroid trail project. I understand the thing I have to do, to identify asteroids inside the Hubble telescope pictures but since this is my first time seeing it, and I’m doing something intricate, I can definitely make mistakes. I don’t think I’m qualified/ but if the point of this is to have multiple look at it, on multiple occasions for quality check. Then it works?
I spent a few minutes transcribing the records of prisoners on Zooniverse. The instructions were very simple, as all I needed to find was the number of offenses and first and last dates of conviction for each criminal. It took some time to figure out what to look for the first time, but after that it became much easier to read the handwriting, since all I was really looking for were dates. I think that I was able to transcribe around 10 records, which I know is a minuscule amount in terms of the project, but it is still very cool to know that I was able to contribute to the project.
I found it very interesting from a humanities perspective to be able to look at the primary source as I was transcribing. Since interacting with Zooniverse is totally optional, I feel like there are likely very few ethical dilemmas. Since people who choose to participate would be doing so because of their own interests, there is probably not a huge problem with people trolling, and no one is being forced to do unpaid labor.
I worked with the Worlds of Wonder project and looked for figures in a German science book (Zeitschrift für wissenschaftliche Microskopie). One of the challenges was that the magazine was in German, which proved to make answering questions difficult. If there was a figure, I would be asked to caption it. However, sometimes there was no caption to transcribe at all and I was unsure what to do when they gave me an empty text box. The feature didn’t let me put nothing at all, so I sometimes had to just fill in the information with a vague word describing a scientific instrument I was quite confused by.
The instructions were quite easy to follow, but I was unsure how accurately I was completing the project. This makes me wonder how the researchers approach quality assurance? It is quite possible that the people contributing to the projects don’t really know what they are doing or get lazy. However, I had a lot of fun interacting with the historical documents. I especially enjoyed the historical skies project that involved mapping constellations. I’m not sure how much of a contribution I was really making as I don’t know how the data I created will be used. I drew boxes around the various images of constellations, but it is very possible I missed a couple. Are these images then separated from the whole and analyzed separately? All in all, I thought this website was really cool because I loved interacting with the primary sources. It is very valuable just for the fact that it makes these records available to the public.
With the criminal characters’ project, it was extremely hard to read the text and transcribe it. Because it was handwritten in cursive, I really struggled to decipher what the word was exactly and at times couldn’t tell if it was one number or the other. Navigating the page was also a slight struggle for me which also made it hard to transcribe. I had a hard time zooming in on the page as well as navigating through the page while it was enlarged.
I found it a little easier to use a mouse rather that my trackpad. I also made the mistake of scrolling lightly through the instructions, so navigating the toolbar was difficult for a while.
The site asked me to input details of the location, time, name, colour, etc. of Californian Plants. It was very simple if I got confused there was box to help clarify what it was asking me. It did make me feel like I was contributing to the scientific community, however, i am skeptical about how this data is being used and the checking mechanisms behind the program. If i was to misidentify something would it ruin the form? Overall I enjoyed my experience but was anxious that I would incorrectly input a name or mess something up.
I worked at the project “Fossil Atmospheres”, and it’s not hard. I just need to recognize two different kind of cells and signify it. I think this platform really helps projects like Fossil Atmospheres because it offered a new way of doing things and declined the cost of making a project.
I worked a little on the Measuring the Anzacs project and the thing I was most struck by was the steep learning curve that was needed to actually contribute to the project. Even as someone who is generally interested in helping out with such project, the lack of background knowledge I had with the project meant that I was second-guessing everything that I was inputing, and generally wanting to skip anything I wasn’t 100% sure of. I know you can get better at these projects, having contributed to transcription projects in the past, but with that I had easy access to professors who could answer questions. I did notice, however, that there was an option to speak with someone who worked on the project as an attempt to address that problem. That’s probably the best solution that can be offered with this format.
I worked on Worlds Of Wonder. It was simple enough. Locate an illustration in a book, figure out what kind of image it was, and attempt to transcribe its caption. While I did get to do it for a couple illustrations, for each illustration there were 20 odd pages that didn’t have one that I had to scroll through. Transcription wasn’t in English, but the pages seemed to be pushlished text, so it was at least easy to read. I felt as though my contribution was important, assuming I was told to look at pages that had not yet been looked at, but it felt like they were using my labor more to identify the rare page that did have an illustration, and cared less about how I did transcribing it.
I thought the instructions on the Worlds of Wonder website were very straightforward. I worked on finding microscopic diagrams from the 1800s. I identified pictures, captions, and manufacturers. I had to move my window a bit in order to control their square tool correctly. (The instructions said to put a square around the illustrations or pictures. On pages where there were multiple pictures, it was hard to select all.) I also had to enter keywords, and that proved to be difficult, especially with pages without words. They said I could like a button for more information, but I could not locate the button. Overall, I understood the process after couple pictures, and I had a fun time helping out the project, even if it was just a few illustrations.