
In our continuing quest to explore what goes on “under the hood” of digital humanities projects, this week we are moving from the front-end client-side user experience to the database “back end” on the server side, where all the data storage and information retrieval magic happens. In order to perform analysis, or present the results of our research to the public on the web, we first need to collect, categorize and store our data in a way that will give us the best combination of structure and flexibility.
You can use a simple flat spreadsheet to store enough data to power some pretty impressive applications using JavaScript alone, like using the Google Maps API or the beautiful TimelineJS framework.
In the past, students in this class used the TimelineJS framework to make Timeline of Carleton History, and the backend was nothing more than a simple Google Sheet.
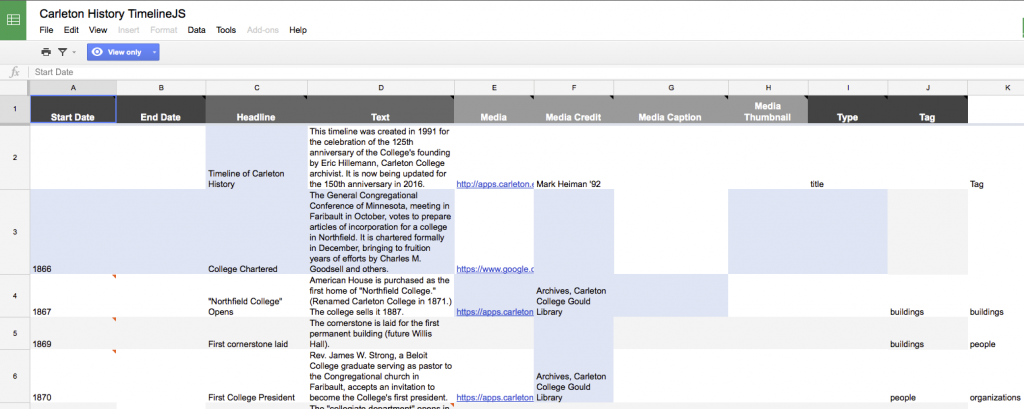
This works great for the timeline, but what if we wanted to do different things with the same data? What if we wanted to reorder our data by something other than chronology, or extract all the people or buildings, or add spatial locations? And what if we wanted to model the relationships between those elements? Our spreadsheet is just not flexible enough for this. In order to store complex data sets, we need a more sophisticated way to store it; enter the relational database.
There is a vast amount of literature out there on database design theory and practice, but the articles we read for this week provide a good starting point into the general characteristics of relational databases, and the raging debates over how to move beyond them in the brave new world of ‘big data‘ in humanities research.
The key takeaway from these debates is that “data” are not value free and neutral pieces of information. Any time we break information down and classify it into categories, we are imposing our human world view and experiences on the information, whether consciously or not. This is unavoidable, but the best way to deal with it honestly is to acknowledge our biases, document our decisions and explain our thinking at each step of the process. The resulting metadata (data about the data) are critical for successful scholarly projects, and we will discuss their importance throughout the course.
For today though, we are interested primarily in exploring how relational databases work in a typical DH project, which often shares a lot of similarities with how web applications work in general.
SIDE NOTE: In the past few years, there has been an increasing call to move away from CMSes and database-driven sites and back towards static websites. This is not pining for the bad old days, but instead relying on the increasing number of static site generators like Jekyll that let you build the site locally on your machine and push static HTML to a host rather than reacting to user requests and populating HTML with content as in most database-backed web sites. While there are many benefits to this approach, especially for fairly simple sites like blogs and those without much user interaction, there are some drawbacks to static site generators for DH projects, knowing how databases interact with client side systems is still a valuable skill, which we will be focusing on in this course.
In Class: Crowdsourcing
Explore the Measuring the Anzacs project and work your way through at least one document, marking and transcribing the text.
When you’re done, post a brief comment below giving some feedback on the process. Were the instructions easy to follow? Was the text easy to transcribe? Did you feel like you were making a real contribution to the project? What did you get out of the project, from a humanities perspective? Did you come away with a greater understanding of either the research process or the lived experience of the individual people whose records you were working with?
Assignment: Metadata and Zotero
Brandon Walsh has created a helpful online book with resources and lessons on text analysis (which we’ll discuss in more detail later in this course). He includes a good discussion on metadata and the importance of data cleaning — which is a fundamental step in any project, whether storing data in a flat table or relational database.
Read through the post on data cleaning, and how to setup up Zotero, if you haven’t already. Think about how the metadata are stored and how this database works, as opposed to the WordPress instance. We will discuss these ideas and what we can do with this data in class on Friday.
