Over the past few weeks we have discussed and seen how the modern dynamic web—and the digital humanities projects it hosts—comprise structured data (usually residing in a relational database) that is served to the browser based on a user request where it is rendered in HTML markup. This week we are exploring how these two elements (structured data and mark up) come together in a mainstay of DH methods: encoding texts using XML and the TEI.
XML (eXtensible Markup Language) is a sibling of HTML, but whereas the latter can include formatting instructions telling the browser how to display information, the former is merely descriptive. XML doesn’t do anything, it just describes the data in a regularized, structured way that allows for the easy storage and interchange of information between different applications. Making decisions about how to describe the contents of a text involves interpretive decisions that can pose challenges to humanities scholarship, which we’ll discuss more in the next class on the Text Encoding Initiative (TEI). For now, we’re going to explore the basics of XML and see how we can store, access, and manipulate data.
We went over the main parameters in class, but an excellent primer to XML in the context of DH has been put together by Frédéric Kaplan for his DH101 course and can be viewed in the slideshow below.
Exercise
Since XML is like a database in plain text, we can store it anywhere and use pretty much any programming language to perform operations on it, transform it and dictate how it should be displayed. For this exercise we will extract a simple RSS feed’s data (a ubiquitous form of XML document) and output it as HTML using three different languages: JavaScript, PHP and XSLT. Two of these we’ve already encountered, but more information on all three can be found in the resources section below.
- Download the zipped exercise files here.
In order to run the scripts you’ll need to put them in the web root of a server environment. For us, that means the public_html directory of your ReclaimHosting server.
- Log in to your ReclaimHosting.com account
- Click on File Manager
- Navigate to your public_html directory
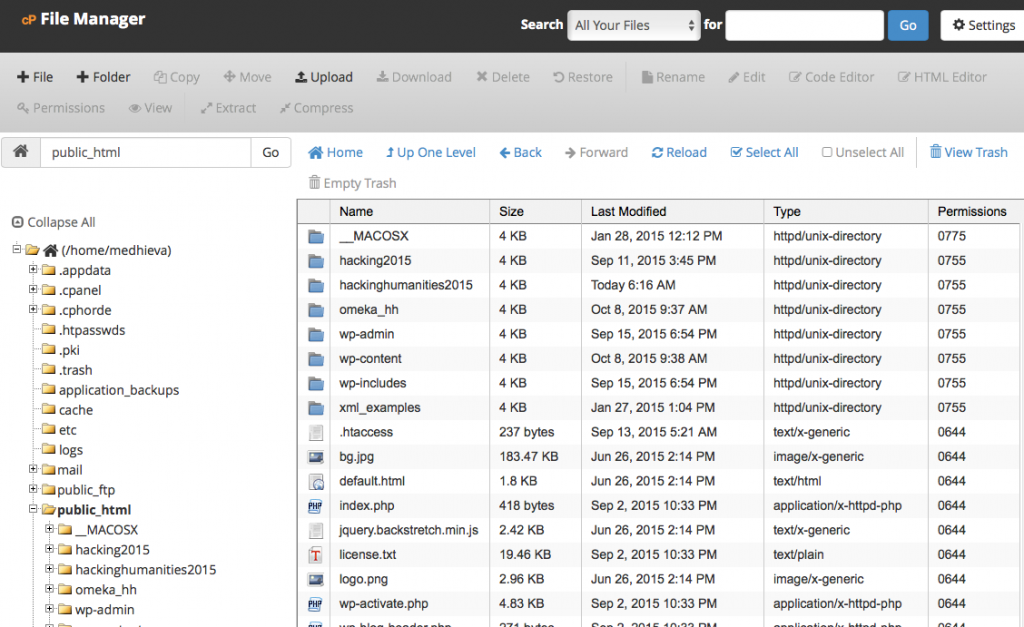
- Click the Upload button and choose the xml_examples.zip file from your local machine.
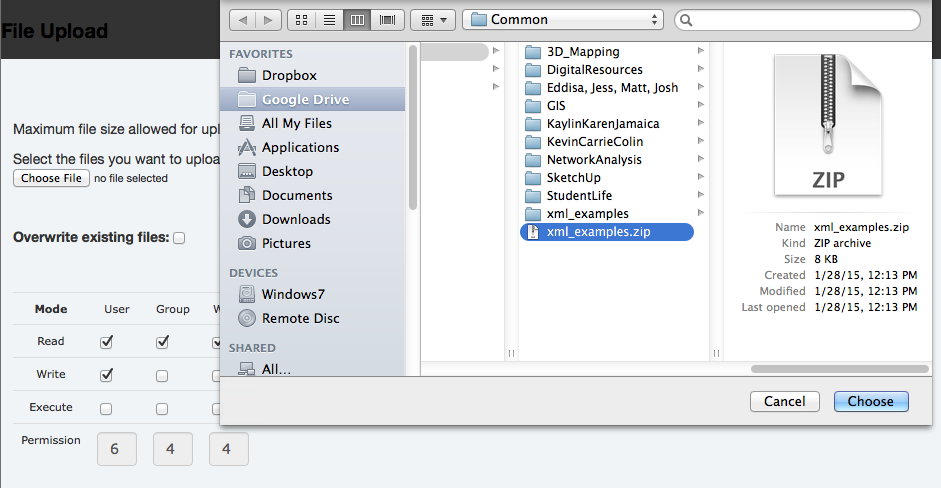
- Right-click on the zipped file and Extract the contents.
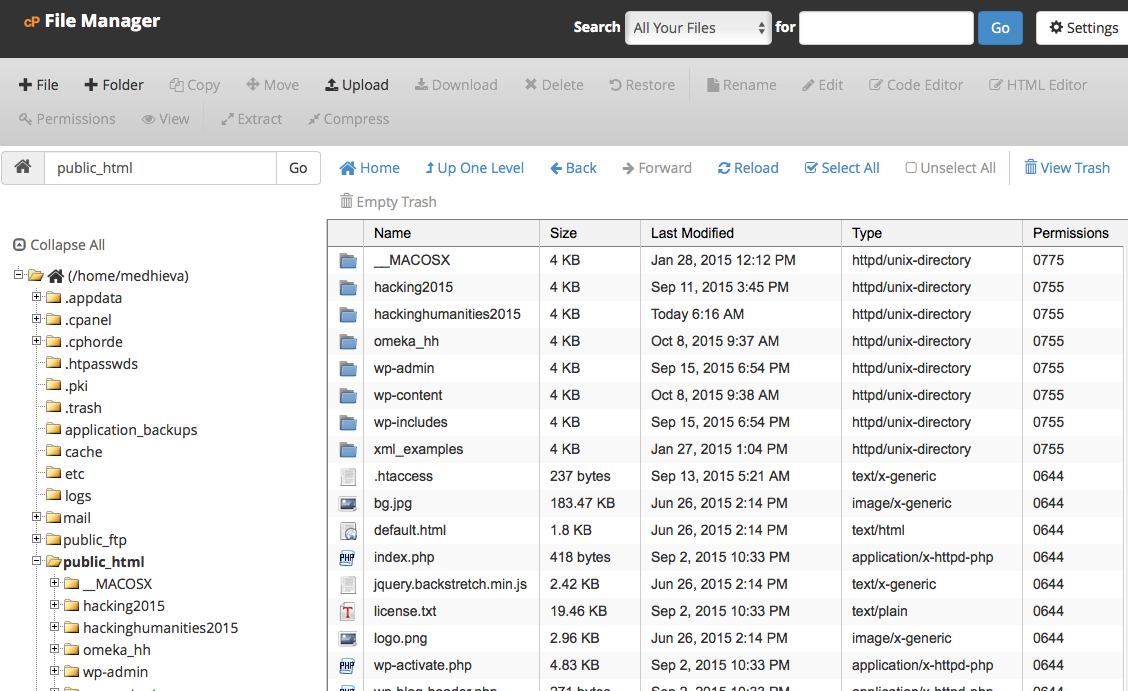
You should have a new xml_examples folder containing the following files
- feed.xml (the data)
- ParseXML.html
- ParseXML.php
- xls_examples
- ParseXML.xsl
- feed_xsl.xml
Examine the various files in both a text editor and browser and try to figure out what they do. The cPanel offers a built in code editor and text editor, which you can access via the buttons at the top of the file manager window or by right-clicking.
- Open the feed.xml file in the Code Editor and plain Editor to see how they differ.
- Check out the other files too and see if you can figure out what language they are using and how they are manipulating the DOM.
These small scripts will transform the underlying data in the xml file and render it to the browser as a simplified list. Any thing you put in your public_html folder can be accessed directly in a browser underneath your top domain.
- Open a new browser window
- Go to “yourdomain.com”/xml_examples/ParseXML.html
- Right click and view the page source or inspect elements using DevTools
Repeat the process with the PHP file.
- How are they similar and how do they differ?
- Are some languages easier for you to understand?
- Look at how they navigate the hierarchical node tree and compare the XML DOM to the HTML one.
Start hacking on them to see if you can change the elements being selected or alter how they are being output to HTML;
- Can you swap out the <description> for the <link> text?
- Can you make the description text link to the event URL?
Going Further
RSS feeds are ubiquitous, and are a good way to practice with the structure of XML. But for DH projects, you are probably going to want to get data from a more scholarly resource, like an Omeka repository for instance.
Omeka allows you to access an XML output of a list of items in any repository, so to explore further:
- Log into our Omeka repository on Carleton’s Buildings
- Go to the Items list and scroll to the bottom to access the Output Formats
- Download the omeka-xml file and/or the rss2 file
- Upload this to your xml_examples directory and see if you can hack the scripts to extract and print some information you are interested in.
Resources
XML DOM and JavaScript
w3schools is always a good place to start for the by-the-book definition of a language or standard with some good interactive examples, and their XML DOM tutorial is no exception.
SimpleXML in PHP 5
If your project allows server-side scripting it is MUCH easier to use PHP to parse XML than JavaScript. The w3schools introduction to simpleXML in PHP 5 is solid, but TeamTreehouse.com has a more readable and accessible real-world example of how to parse XML with php’s simpleXML functions.
XSLT
XSLT (eXtensible Stylesheet Language Transformations) is to XML what CSS is to HTML, but it’s also a lot more. More like a programming language within markup tags than a regular markup language, it’s a strange but powerful hybrid that will let you do the same things as the languages above: transform XML data into other XML documents or HTML. Learn the basics at w3schools’ XSLT tutorial. If you’d like a more in depth explanation of how XML and XSLT work together check out this tutorial xmlmaster.org, which is geared at the retail/business world but contains basic information relevant for DH applications.